About the platform
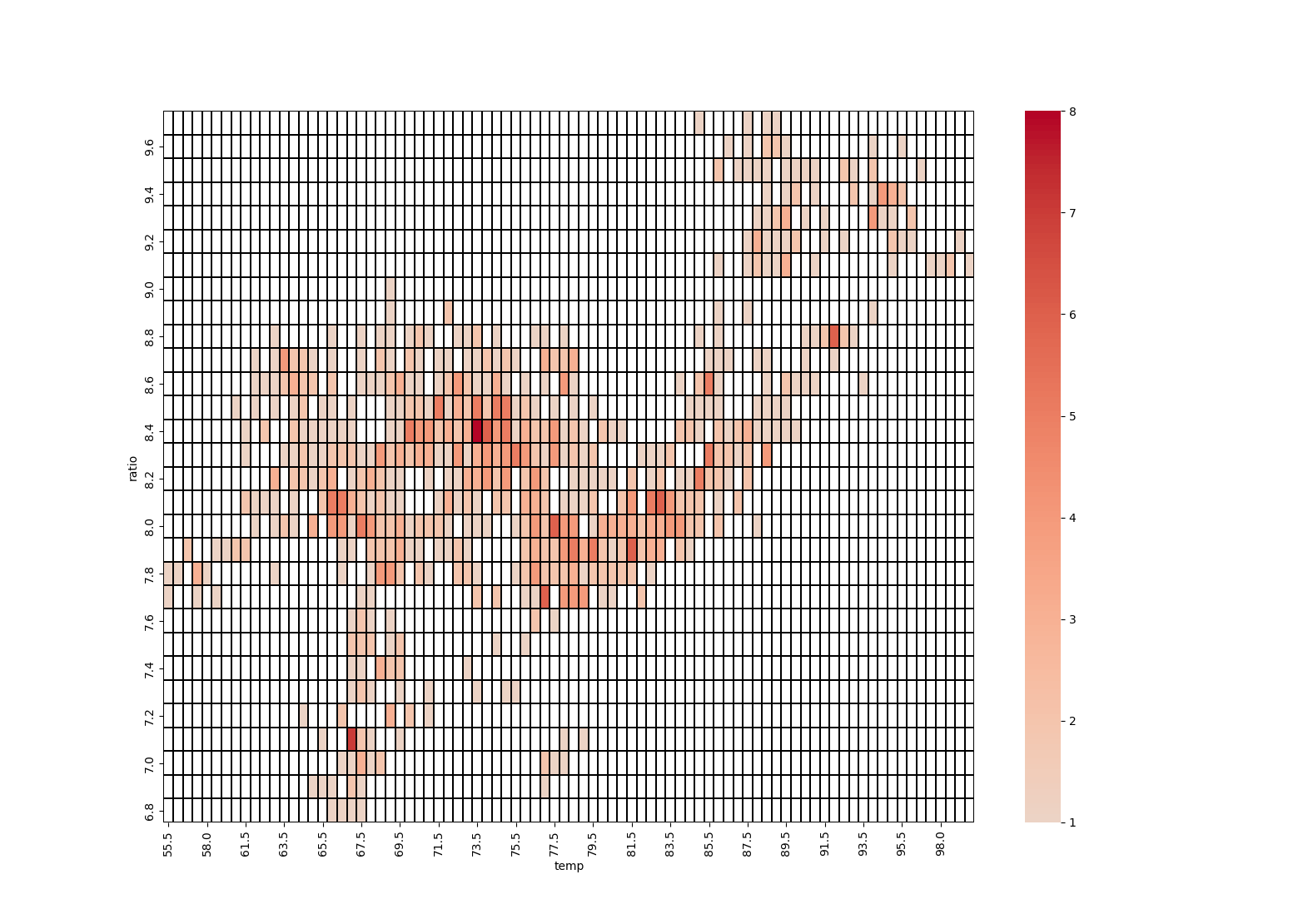
This digital platform is for public health informatics and technology online training. The digital platform contains valuable algorithms to process public health data. It has direct access to FHIR server, EHR and decision support systems, machine learning and deep learning algorithms, access to cloud technologies and big data platforms. The platform contains real-world data sets and data exploration algorithms based on Python programming.
Training:
We divide training into 3 categories:
1) beginners: this platform contains all elements including EHR, Python algorithms for data preprocessing, access to Tableau, real-world data sets, etc. to train undergraduate students in public health informatics and technology.
2) working professionals: this platforms contains a complete set of elements to train participants in public health data analytics, data science, and information systems including FHIR/API server for data exchange, EHR/DSS system for public health decision support, and predictive analytics to detect and predict public health challenges including outbreaks and pandemics,.
3) advanced workforce: this platform contain a complete set of elements to train advanced PHIT workforce in modern IT technologies including machine and deep learning, AI, big data and cloud technologies.

Curricula:
Beginners: The curriculum for beginners focuses on data collection, data storage, data preprocessing, and data visualization.
Working professionals: The Curriculum for working professionals focuses on computational epidemiology, data storage management, Python programming, public health information systems, fast data interoperability (FHIR), application of programming interfaces and other tools that enable to significantly optimize PHIT applications.
Advanced training: Finally, the advanced training focuses on applications of AI, machine learning, deep learning, big data analytics, and cloud technologies to facilitate operations with multi source public data. The participants will learn how to use open-source libraries such as TensorFlow and Keras with high-level APIs, Spark and Hadoop, Sage-Maker processing to optimize computations focusing on real public health data collected from different sources.

Spring 2024 training: to advance your career in public health informatics and technology
Because of a rising interest in big data analytics, the October boot camp will focus on public health informatics and technology topics in the big data ecosystem. The success of Big Data ecosystem setup depends on the tools and techniques used by healthcare organizations in the upcoming years, including lowering health care costs, better diagnosis and prediction of diseases and their spread, and much better responding to public health problems such as preventing and responding to public health emergencies.
The students will learn how to work with distributed file systems in public health informatics, get acquainted with the Hadoop ecosystem, understand the optimization of MapReduce calculations and work with Hive to solve realistic public health problems, to work with Spark: from basic terms and RDDs to Spark DataFrames and Spark computing optimization applied to public health data sets, how to work with streaming data processing, get acquainted with Kafka and Spark Structured Streaming, master NoSQL on top of big data. This knowledge will be important to approach critical importance problems in public health that require streaming data with fast interoperability (FHIR) using web services (API).
Over 200 individuals are taking the course. To subscribe for the fall course, please send a request for the application form to [email protected].